Working with HiPerGator
HiPerGator is a supercomputer at the University of Florida. It is a cluster of computers that can be used for high performance computing.
The main purpose of HiPerGator is to provide a extremely powerful computing environment for researchers at UF. For IC3, we will mostly apply HiPerGator to:
- run our large-scale data processing pipelines, ETL pipelines and data analysis pipelines
- train and evaulate our machine learning models
- deploy our data commons and data services
This document will focus on how to use HiPerGator efficiently, and try to provide the sample codes and templates to run your own projects. To learn more details about HiPerGator, please refer to HiPerGator Documentation
HiPerGator Architecture
this is a simplified version for easy understanding
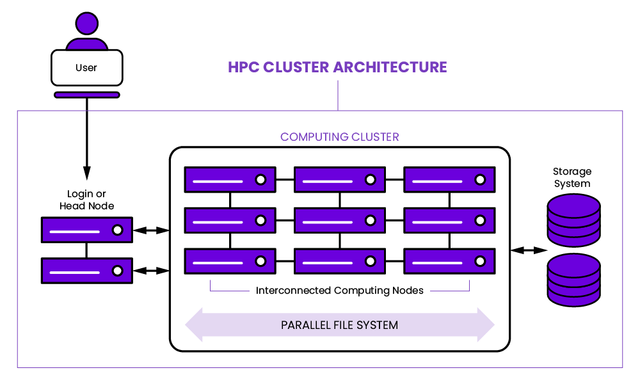
The HiPerGator cluster consists of a number of compute nodes, a number of login nodes, and a number of storage nodes. The compute nodes are where the actual computation happens. The login nodes are where you log in to the cluster and submit jobs to the compute nodes. The storage nodes are where the data is stored.
HiPerGator Access
There are multiple ways to login into HiPerGator.
- SSH
- Jupyter
- OnDemand
To login to HiPerGator directly, you need to use SSH.
ssh <username>@hpg.rc.ufl.edu
To work with Jupyter server directly.
Please refer to the detailed documentation here to learn how to use JupyterHub on HiPerGator.
This is a recommended way to apply with HiPerGator interatively.
Please refer to the detailed documentation here to learn how to use OnDemand on HiPerGator.
HiPerGator File System
- Home Directory -
/home/<username>, it's used mainly for storing your personal files, please do not store large files here. - Blue Storage -
/blue/<groupName>, it's used for storing high performance data, please store your codes and results here. - Orange Storage -
/orange/<groupName>, it's used for storing archive or backup data, please do not store your codes and results here.